한국어 언어모델은 얼마나 안전할까? 유해 프롬프트에 대한 대응 분석공개 한국어 언어모델의 취약성 분석: 15개 주요 언어모델의 안전성을 철저히 분석했더니, 최대 78%의 유해 요청을 수락하는 충격적인 결과가 나왔습니다. 하지만 우리는 이 문제를 해결할 수 있는 세 가지 실용적인 방안도 함께 제시했습니다.Oct 30, 2024Oct 30, 2024
두번째 논문을 쓰고 느낀 것들좋은 글을 쓰는 것은 너무나 어렵다. 남들은 어떻게 좋은 글을 쓸까 고민했고, 유명한 논문들을 다시 읽었다. 그들이 쓴 단어들과 접속사들을 다시 면밀히 살펴봤다. ChatGPT와 Grammarly의 도움도 적극적으로 받아서 더 나은 표현을 찾았다…Mar 5, 2024Mar 5, 2024
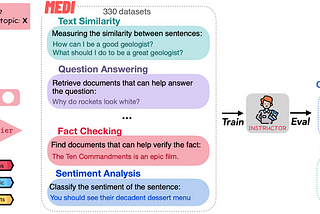
INSTRUCTOR하나의 모델에서 여러가지 NLU task를 수행할 수 있는 모델이 나왔다. task instruction이 추가된 text embedding을 이용한다.May 19, 2023May 19, 2023
Adafactor Optimizer for Deep Learning메모리 사용량이 적으면서 learning rate도 알아서 찾아주는 Adafactor에 대해서 알아본다.Apr 25, 2023Apr 25, 2023
Large Language Model의 scaling law와 emergent ability거대한 언어모델(Large Language Model, LLM)을 학습할 때, 우리는 한정적인 리소스로 최적의 모델을 학습해야 한다. 한 번 학습에 큰 비용이 들기 때문에 여러번 실험하기 어렵다. 공개된 문헌을 바탕을 연산량, 데이터 크기, 모델…Apr 23, 2023Apr 23, 2023