이 글은 Full Stack Deep Learning의 두번째 코스인 Infrastructure and Tooling을 보고 내용을 정리한 글입니다. 내용의 사진은 모두 발표 슬라이드를 가져왔습니다. 잘못 이해했거나, 의역이나 오타가 있을 수 있습니다. 제보해주시면 감사하겠습니다 🙏

Overview
ML 시스템의 구성요소들(Components)는 무엇인가?
그냥 data를 주기만 하면 알아서 prediction system을 만들고 scalable한 서버나 모바일 기기로 배포된다면 좋겠지만, 현실은 아래와 같은 복잡한 과정을 거쳐야 한다.


구글의 세미나 paper에서 얘기하는 내용을 보면, 우리가 전체 ML 시스템을 볼 때 모델링 코드는 극히 작으며, 시스템을 구성하는 수많은 코드들이 존재한다. 이를 아래 그림처럼 자세히 쪼개보면

Data Component
- Data Storage: 어떻게 데이터를 저장할까?
- Data Workflows: 어떻게 데이터를 처리할까?
- Data Labeling: 어떻게 데이터를 라벨링할까?
- Data Versioning: 어떻게 데이터의 버전을 관리할까?
Development Component
- Software Engineering: 어떻게 적절한 엔지니어링 툴을 고를까?
- Frameworks: 어떻게 적절한 Deep Learning Framework를 고를까(파이토치, 텐서플로우 등을 말함)
- Distributed Training: 어떻게 분산환경에서 학습할까?
- Resource Management: 어떻게 분산된 GPU를 제공하고 관리할건가?
- Hyper-Parameter Tuning: 모델 하이퍼파라미터를 어떻게 튜닝할까?
Deployment System
- CI & Testing: How to not break things as models are updated?- 모델을 업데이트하더라도 문제가 없도록… 같은 의미인듯
- Web: 웹 서비스에 어떻게 배포할까?
- Hardware & Mobile: 임베디드/모바일 시스템에 어떻게 모델을 배포할까?
- Interchange: 시스템 간의 모델을 어떻게 배포할까?
- Monitoring: 모델 예측을 어떻게 모니터링할까?
각각의 이슈를 돕기 위한 툴들이 있으며, 또한 이것들을 All-in-one으로 제공해주는 툴들도 존재한다.
궁극적인 목표는 데이터만 집어넣으면 이것들을 “알아서” 해주는 시스템을 만드는 것이다.
Software Engineering
ML Developer에게 가장 좋은 소프트웨어 엔지니어링 관행들은 무엇일까?
- 우선 언어로는 Python이 압승했다.
- 실험적 분석을 하거나 빠른 프로토타이핑을 위해 Jupyter Notebook이 대세적으로 사용되고 있다. 하지만 상용 제품에는 적절치 않다(고는 하나 Netflix처럼 Jupyter Notebook을 이용해서 ML workflow를 만든 사례도 있다).
- Python 프로그래밍을 위해서는 VSCode나 PyCharm이 훌륭한 도구이다.
이부분은 그냥 빠르게 넘어갔음
Computing and GPUs
필요한 계산량을 위한 적절한 하드웨어를 어떻게 선택할 수 있을까? GPU를 직접 구해야할까 혹은 클라우드를 이용해야할까? 우선 환경에 따라 필요한 계산량을 보면

개발환경에서는 코드작성/디버깅/빠른 트레이닝을 위해 1–4 GPU를 가진 데스크톱이나 클라우드 인스턴스면 충분하다. Training/Evaluation 단계에서는 며칠이 소요될 정도로 많은 계산이 필요하다. 모델 아키텍처, 하이퍼파라미터 검색 작업과 큰 모델 학습을 위해 클러스터급의 많은 성능이 요구된다. 또한 빠르게 실험을 개시하고 결과를 리뷰할 수 있기를 원한다.
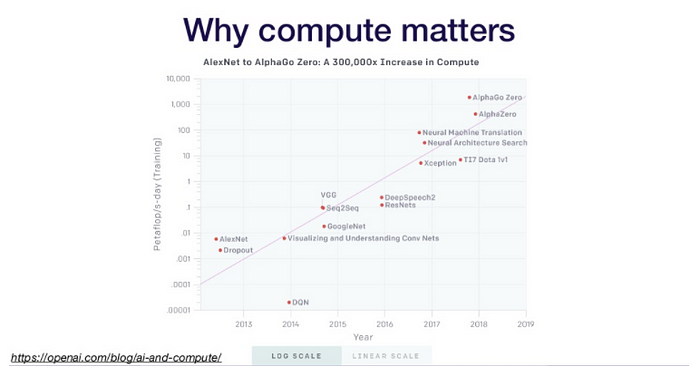
OpenAI 리포트에 따르면 최근 AI 기술들은 점점더 많은 계산량을 요구하고 있다. 하지만 창의력을 발휘한다면 적은 계산량으로도 뛰어난 성능을 보여줄 수 있다.

그래서 결국 GPU냐 클라우드냐를 고르기에 앞서 간단히 GPU에 대해 알아보자. GPU는 Nvidia 제품만이 유일하다. 현재로서 가장 빠른 옵션은 GCP에서 사용 가능한 Google TPU다. 타 기업들도 시도중이지만 아직은 별로다.

이후 NVidia GPU 들의 아키텍처와 성능에 대한 얘기가 나오는데 요약하면
- Use-case: Server 라고 써있는걸 먼저 사라, 그다음에 Enthusiast(열성가? 매니아? 라면 쓰라는 것 같음)
- 필요한 배치 크기를 확보하기위해서 메모리를 잘 보고 골라야한다.
- Tensor TFlops나 16bit 지원여부가 RNN등 일부 모델에서는 중요하다고한다. 계산속도는 두배빠르고 메모리는 1.5배 덜 쓴다고 한다.
- cost 에서 used는 중고를 의미하는듯
- 아키텍처는 Volta, Turing 이후로 사고 그 이전은 사지 말라고한다. Pascal은 중고로 싸게 사는건 괜찬다고.
- 이게 2019년에 나온거니까 올해는 또 다르겠지
클라우드 제공자들
- AWS: 비싸다, 쓸거면 Spot Instance를 써라
- GCP: CPU랑 GPU를 다른 인스턴스끼리 붙일 수 있다고 한다. AWS는 그게 안된다고(2019년 얘기니까 지금은 될수도)
- 스타트업이면 Paperspace나 Lambda Labs가 가성비좋은 선택지다.
- 홀로 연구하거나 스타트업이면 최신 아키텍처 GPU 4개로 개발하고 학습이나 다양한 실험은 Cloud로 하는게 좋다.
- 큰 직장이라면 개발과 학습 모두 클라우드에서 해도 좋다. 실패 관리를 위한 인프라나 리소스가 잘 준비되있기 때문.
직접 데스크톱을 준비하면
64GB RAM + RTX 2080 Ti 4x 면 대충 $7000… GPU4개를 넘어가면 엄청 힘들어진다고 한다. 조립하고 세팅하는데만 하루는 걸릴 것이라고, Lambda Labs나 NVIDIA에서 파는 pre-built 장비를 구매하는 옵션도 있다.

장비를 직접 구매하는게 쌀지는 직접 봐야한다. 위 사진의 예시로 $10000짜리 장비는 대충 5–10주간 클라우드에서 학습을 돌릴 수 있는 양이다. 또 직접 고성능 데스크탑을 제작하는게 pre-built나 클라우드보다 훨씬 저렴할수도 있다. 클라우드가 비싸더라도, 실무에서는 미래에 더 큰 스케일링이 필요할 수도 있다. DevOps등을 하기에는 클라우드가 더 편리하다.
Resource Management
컴퓨팅 자원을 어떻게 효과적을 관리할 수 있을까? 여러 사람이 여러 GPU/기기를 다른 환경에서사용해야한다. 실험들을 쉽게 진행할 수 있게 하고 거기에 적절한 리소스 할당과 의존성을 갖게하는것이 목표이다.

우선 제일 간단한 방법은 위처럼 스프레드 시트를 만들어서 예약하는것. 놀랍게도 많이 사용되는 방법이다 (ㄷㄷ;;). 다른 방법은 스크립트를 짜서 스케쥴러에게 주면 스케쥴러가 알아서 리소스를 할당하고 실험을 진행하는 방법이다. 다른 일반적인 방법은 오커와 쿠버네티스를 이용한 방법이다. 도커로 가상환경을 만들고 쿠버네티스로 클러스터에서 도커 인스턴스들을 관리하는 것이다. 추가적인 방법으로는 Kubeflow나 Polyaxon같은 오픈소스를 활용하는 방법이 있다.
Frameworks and Distributed Training
어떤 딥러닝 프레임워크를 고를까? 내 모델을 어떻게 분산학습할 수 있을까?
- 특별한 이유가 없는이상 Tensorflow 혹은 Pytorch를 써야한다. 둘 다 연구와 프로덕션 환경에 좋아지도록 개선되고 있다.
- 빠르게 반복하기를 원하는 초보자들에게는 fast.ai가 확실한 선택이다.
분산학습은 Data Parallelism과 Model Parallelism으로 나뉜다.
Data Parallelism
- 반복 학습이 너무 오래걸릴 때 학습 데이터를 쪼갠다.
- CNN의 경우 2/4/8 GPU에서 약 1.9/3.5/5.2배의 속도 향상을 기대할 수 있다.
- 큰 조직에서 프로덕션 레벨 알고리즘을 실행할 때 많이 사용된다.
Model Parallelism
- 하나의 GPU에 모델을 올릴 수 없을 때 사용한다 ㅠㅠ.
- 복잡하고 차라리 더 좋은 GPU를 사는게 낫다
Tensorflow, PyTorch 모두 Distributed 환경을 쉽게 구현할 수 있다. 여러 Machine에서 하려면 좀 복잡해지는데, RAY나 Horovod 같은 더 간편하고 추가적인 기능들이 있는 오픈소스들을 쓰는 방법도 존재한다.
Experiment Mamanagement
각 실험을 어떻게 트래킹할 수 있을까? 하나의 실험을 하더라도 그 가중치와 하이퍼파라미터, 코드, 학습 결과를 기록해야한다. 여러 실험을 할수록 그 결과물을 관리하기 어려워진다.
- Tensorboard: 아주 간단하게 실험결과를 모니터링할 수 있다. 나머지 부가적인 기능들(코드 저장, 하이퍼파라미터 기록)
- Losswise: 에폭마다 git commit을 만드는 방식으로 결과를 저장한다. 시각화 기능도 제공한다.
그 외에는
- Comet.ml
- Weights & Biases
- MLFlow
등이 있다. 강연자는 MLflow를 쓴다고 함.
하이퍼파라미터 튜닝
어떻게 하이퍼파라미터를 튜닝할까? 딥러닝은 말그대로 하이퍼파라미터로 가득하다. 수많은 하이퍼파라미터로 구성된 다차원 공간에서 최적의 설정을 찾는건 쉽지 않다. 하이퍼파라미터 검색은 계산능력이나 돈, 시간에 제약을 받는 반복적인 작업이다. 그래서 하이퍼파라미터를 찾아주는 소프트웨어를 사용하는데 굉장히 도움이 된다.
- Hyperopt: 쉽게 하이퍼파라미터를 찾아주는 파이썬 라이브러리
- SigOpt: Optiomization-as-a-Service API
- Ray Tune
- Weights & Biases
등이 있다.
All-in-One Solutions
올인원 솔루션은 여태까지의 것들을 모두 제공해주는 솔루션이다.
- Facebook의 FBLearner Flow
- Uber의 Michelangelo
- TesnsorFlow Extended(TFX)
- Google의 Cloud AI Platform
- Amazon SageMaker
- Neptune
- FloydHub
- Paperspace
- Determined AI
- Domino Data Lab
쭉 보면서 정말 벌써부터 많은 솔루션들이 등장했구나 느낀다.
